


 摘要:
...
摘要:
... 界面新闻记者 |
大模型一周年之际,业界对各类工作的重要程度开始达成共识,比如多位开发者就公认,扩展大模型上下文长度是非常重要的工作,甚至会成为大模型落地的瓶颈,向量数据库则是另一个。
从ChatGPT的4K到GPT-4的32K,从MPT-7B的65K到Claude的100K,进入下半年,大模型的上下文窗口正变得越来越大。为在长文档问答、长文本摘要和RAG(检索增强生成)等多种应用场景中迅速落地,国内方面以百川智能、月之暗面、智谱AI为代表的大模型头部公司纷纷加入上下文窗口竞逐赛。到了年尾时段,王小川似乎又找到了另一种令大模型走向实用的方法,即与自己曾经最擅长的领域——搜索结合起来。
“今天大模型领域有三大问题要去解决,第一,幻觉要通过更大的模型去减少;第二,模型是静态的知识库,需要升级,之前像OpenAI GPT4停在2019年的数据,到现在最新更新到2023年4月份,停在那里不动;第三,今天尤其在垂直领域里面,做商业落地的时候,专业领域知识不足,每个企业都有自己的垂直数据,还有公开的网络数据,如何利用起来。”12月19日下午的一场交流会上,百川智能CEO王小川对界面新闻等媒体提出了对行业的预判,“光靠模型本身做得再大都是不够的,大模型+搜索才能构成完整的技术栈。 ”
简单说,王小川的意思是指,搜索增强才是大模型落地应用的关键。
当日下午,百川智能宣布开放基于搜索增强的Baichuan2-Turbo系列API,包含Baichuan2-Turbo-192K及Baichuan2-Turbo两款产品。在支持192K超长上下文窗口的基础上,百川还发布了搜索增强知识库的能力,可以让企业从私有化部署上把云端知识上传,做成一个外挂系统,跟Baichuan2系统做对接,这样,每个企业就可以定制自己的硬盘,做到即插即用。

百川智能的Baichuan2-192k大模型是10月30日发布的,其依靠高达192k的上下文窗口长度,居全球上下文窗口之首。此番发布的Baichuan2-Turbo-192K比之前的运行速度更快,效率精度更高。据悉,百川智能通过长窗口+搜索增强的方式,在192K长上下文窗口的基础上,将大模型能够获取的文本规模提升至5000万tokens(大模型处理文本时的最小单位),相当于1亿汉字。


百川智能联合创始人洪涛对记者解释称,百川的整个搜索增强知识库是可看作是一个外挂的硬盘,而上下文窗口在百川体系里相当于内存,“Baichuan2-192k可以一次容纳35万汉字,这次测试的知识库相当于5000w token,接近1亿汉字,整整高两个数量级,可以理解成现在的电脑内存是G级别,硬盘是T级别。 ”
目前,用户可通过官网入口体验搜索增强和长窗口加持后的通用智能。从现场演示可以看出,搜索增强的确能有效解决大模型落地应用的诸多问题。
在具体实施上,模型是先根据用户的提示词,在海量的文档中检索出最相关的内容,再将这些文档与提示词一起放到长窗口中,从而节省推理费用与时间成本。
在现场演示中,百川智能的知识库可以推断出用户输入背后深层的问题,能理解用户的真实意图,能引导模型回答出更准确的答案。
为精准理解用户意图,百川智能使用自研大语言模型对用户意图理解进行微调,已经有能力将用户连续多轮、口语化的提示词Prompt信息转换为更符合传统搜索引擎理解的关键词或语义结构。
王小川解释称,他们是通过稀疏检索和向量检索跟搜索的系统对接的方式,攻克了一部分技术难点,达到了语义理解方面的更好效果。首先,百川智能为了让向量模型实现更好的检索效果,融入了稀疏检索这样的模型,而这个“来自于此前搜索的多年积累”;其次,“用户需求是口语化、复杂的上下文相关的提示词prompt,而传统的搜索是基于一个关键词Prompt,这两个对齐是今天搜索长窗口要面临的问题。”
据百川智能技术联合创始人陈炜鹏介绍,当下,构建大模型知识库的主流方法是向量检索,但其效果过于依赖训练数据的覆盖,在训练数据未覆盖的领域泛化能力有明显折扣,本质上,向量数据库的检索方式性能较低,只适用于规模较小的企业团队,而稀疏检索对严格的语义、漂移和效率都有更好的表现,并且用到的正是搜狗过去做搜索引擎时基于符号的搜索方式。
目前,百川正在深入探索稀疏检索与向量检索并行的混合检索方式,并做到了将目标文档的召回率提升到了95%的成果,大幅领先于市面上绝大多数开源向量模型的80%召回率。

“召回率越高,准确度越高,这样搜索系统会使得大模型工作得更好。”王小川表示。
此外,百川智能还参考Meta提出的链式验证(Chain-of-Verification,简写CoVe)方法来减少大语言模型幻觉,目前,百川可以做到将真实场景的用户复杂问题拆分成多个独立可并行检索的子结构问题,从而让大模型针对每个子问题进行定向的知识库搜索,提供更加准确的答案。
“在今天尤其从国内来看,搜索增强是大模型走向实用的第一步,甚至是最关键的一步。”王小川坦言。
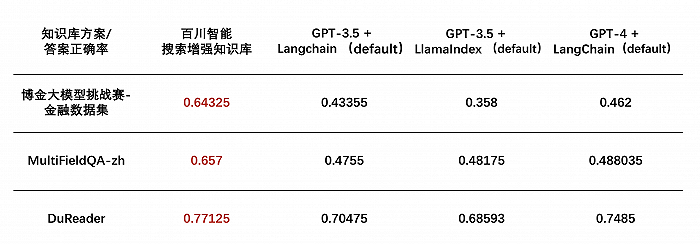
百川智能搜索增强数据库在博金大模型挑战赛中表现不错,在金融数据集(文档理解部分)、MultiFieldQA-zh和DuReader三个行业主流知识库测试集上的得分均领先GPT-3.5、GPT-4等行业头部模型。
这场发布会表面推出了三款产品,实际上也是百川智能首次对外介绍公司的To B业务进展。王小川表示,百川的搜索增强最大意愿并非解决幻觉问题,而是解决可定制化,后者是To B商业路线的最大需求,“光靠一个API调用是不够的”,因为“企业有很多私有数据,如何为模型所用是关键,要通过大模型+搜索增强来实现。”
重B端的同时,百川智能也并没有忽视对C端的探索,王小川也在现场反复提到了对C端产品的看重,还称正在研发几款超级应用。
“C端不会做小”。他表示,搜索增强对B、C两端都很有用,而C端产品有时需要在公域上去做一做,“一方面跟腾讯有合作,一方面我们自己有传统的搜索积累,自研的搜索,尤其是在搜索里面怎么跟大模型对齐,做了非常多工作。”
王小川透露,多家行业头部企业已与百川智能达成合作,包括阿里与腾讯,合作的方式主要包括,在深度融合百川智能长上下文窗口和搜索增强知识库的能力基础上,对自身业务进行智能侧升级。







还没有评论,来说两句吧...